- Hur blir jag av med UTF-8-felet?
- Vad är UTF8-fel?
- Hur ändrar jag kodningen till UTF-8?
- Hur lagras UTF8?
- Hur åtgärdar jag Unicode-problem?
- Vilka karaktärer är inte tillåtna i UTF-8?
- Vad betyder UTF-8 i HTML?
- Varför ersatte UTF-8 ascii?
- Är UTF-8 samma som Ascii?
- Vad är skillnaden mellan ANSI och UTF-8?
- Varför används UTF-8?
- Vad UTF-8 betyder?
Hur blir jag av med UTF-8-felet?
2 svar
- använd ett teckenuppsättning som accepterar alla byte som iso-8859-15 även känd som latin9.
- om utdata ska vara utf-8 men innehåller fel, använd fel = ignorera -> tar tyst bort icke utf-8 tecken, eller fel = ersätt -> ersätter icke utf-8 tecken med en ersättningsmarkör (vanligtvis ? )
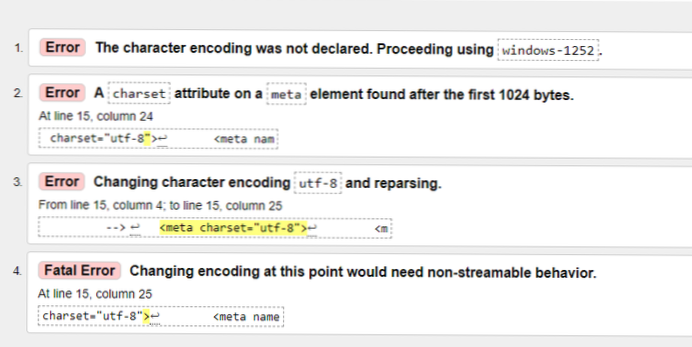
Vad är UTF8-fel?
UTF-8 är det dominerande teckenkodningsformatet på Internet. Det här felet uppstår eftersom programvaran du använder sparar filen i en annan typ av kodning, till exempel ISO-8859, istället för UTF-8. Det finns olika lösningar du kan använda för att ändra din fil till UTF-8-kodning.
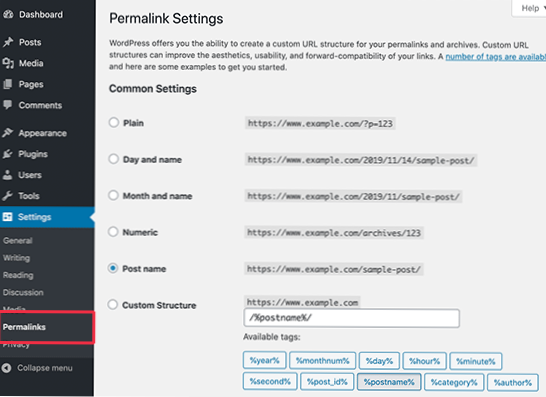
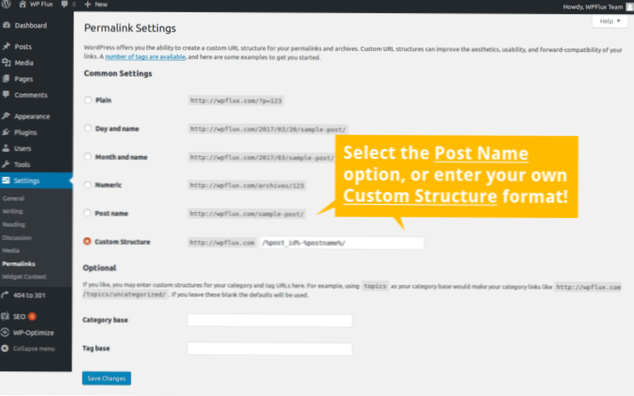
Hur ändrar jag kodningen till UTF-8?
Klicka på Verktyg och välj sedan webbalternativ. Gå till fliken Kodning. I rullgardinsmenyn för Spara detta dokument som: välj Unicode (UTF-8). Klicka på OK.
Hur lagras UTF8?
När programvara som läser UTF-8 stöter på en byte som börjar med 1 räknas det hur många 1 som följer innan de stöter på ett 0. ... Så en byte av formen 110xxxxx säger att de första fem bitarna av ett Unicode-tecken lagras i slutet av denna byte, och resten av bitarna kommer i nästa byte.
Hur åtgärdar jag Unicode-problem?
Det första steget mot att lösa ditt Unicode-problem är att sluta tänka på typ< 'str'> som lagring av strängar (det vill säga sekvenser av läsbara tecken, a.k.a. text). Börja istället tänka på typ< 'str'> som en behållare för byte.
Vilka karaktärer är inte tillåtna i UTF-8?
Observera att ett bytebeställningsmärke (BOM) U + FEFF, även kallat nollbredd utan brott (ZWNBSP), inte kan visas okodat i UTF-8 - byten 0xFF och 0xFE är inte tillåtna i giltig UTF-8. En kodad ZWNBSP kan visas i en UTF-8-fil som 0xEF 0xBB 0xBF, men BOM är helt överflödig i UTF-8.
Vad betyder UTF-8 i HTML?
charset = UTF-8 står för Character Set = Unicode Transformation Format-8. Det är en oktett (8-bitars) förlustfri kodning av Unicode-tecken. Dessa bör belysa förståelsen inom webbutveckling och skript.
Varför ersatte UTF-8 ascii?
UTF-8 ersatte ASCII eftersom den innehöll fler tecken än ASCII som är begränsad till 128 tecken.
Är UTF-8 samma som Ascii?
För tecken som representeras av 7-bitars ASCII-teckenkoder är UTF-8-representationen exakt likvärdig med ASCII, vilket möjliggör transparent migrering tur och retur. Andra Unicode-tecken representeras i UTF-8 av sekvenser på upp till 6 byte, även om de flesta västeuropeiska tecken bara kräver 2 byte3.
Vad är skillnaden mellan ANSI och UTF-8?
ANSI och UTF-8 är två teckenkodningsscheman som används ofta vid en eller annan tidpunkt. Huvudskillnaden mellan dem är användning eftersom UTF-8 har ersatt ANSI som kodningsschema. ... Eftersom ANSI bara använder en byte eller 8 bitar kan den bara representera maximalt 256 tecken.
Varför används UTF-8?
Varför använda UTF-8? En HTML-sida kan bara finnas i en kodning. Du kan inte koda olika delar av ett dokument i olika kodningar. En Unicode-baserad kodning som UTF-8 kan stödja många språk och kan rymma sidor och formulär på valfri blandning av dessa språk.
Vad UTF-8 betyder?
Grunderna i UTF-8. UTF-8 (Unicode Transformation – 8-bit) är en kodning definierad av International Organization for Standardization (ISO) i ISO 10646. Den kan representera upp till 2097 152 kodpunkter (2 ^ 21), mer än tillräckligt för att täcka de nuvarande 1112 064 Unicode-kodpunkterna.